Hello World 😁 💻
No artigo de hoje iremos falar sobre uma estrutura extremamente importante para performance em bancos de dados: os Índices.
O que é um índice?
Um índice em banco de dados é uma estrutura auxiliar que acelera a busca por registros em uma tabela. Ele funciona de maneira semelhante ao índice remissivo de um livro: em vez de percorrer página por página até encontrar o assunto desejado, você vai direto ao ponto.
Imagine uma tabela com milhões de registros. Sem índice, o banco de dados precisa analisar linha por linha até encontrar o dado procurado. Uma query como:
sqlSELECT * FROM users WHERE email = 'x@y.com';obriga o banco a percorrer toda a tabela em busca do valor correspondente. Esse processo é chamado de Full Table Scan.
Quando existe um índice, o banco passa a utilizar uma estrutura organizada que aponta rapidamente onde o dado está armazenado. Em vez de analisar todos os registros, ele segue um caminho otimizado até chegar ao resultado.
De forma simples:
- Sem índice: o banco percorre toda a tabela
- Com índice: o banco vai direto ao dado desejado
Tipos de índices
Os tipos de índices variam conforme a estrutura de dados utilizada pelo banco para organizar as informações e também conforme o objetivo da consulta. Embora a B-Tree seja o modelo mais comum, existem especializações para diferentes cenários de performance.
Índice B-Tree (Balanced Tree)
Esse é o tipo de índice mais utilizado no mercado. Ele organiza os dados em uma árvore balanceada, permitindo buscas, inserções e remoções em tempo logarítmico.
É ideal para:
- Consultas de igualdade (=)
- Consultas de intervalo (>, <, BETWEEN)
- Ordenações
Na prática, é o tipo padrão utilizado em bancos como PostgreSQL, MySQL e Oracle Database.
Índice Bitmap
Em vez de armazenar chaves e ponteiros tradicionais, esse tipo de índice utiliza sequências de bits (0 e 1) para representar a presença ou ausência de valores.
Ele é mais eficiente em colunas com baixa cardinalidade, ou seja, colunas com poucos valores distintos, como:
- gênero
- status
- estado civil
- tipo de pagamento
É muito comum em ambientes analíticos e Data Warehouses, onde há grandes volumes de leitura e poucas operações de escrita.
Índice Hash
O índice Hash utiliza uma função hash para mapear valores a posições específicas.
Ele é extremamente rápido para buscas exatas, como:
sqlWHERE id = 10Por outro lado, ele não funciona bem para consultas de intervalo. Uma busca como:
sqlWHERE id > 100não consegue aproveitar esse tipo de índice.
Seu uso costuma ser voltado para cenários de acesso direto e extremamente rápido, como sessões, caches e identificadores específicos.
GiST e GIN
Esses são índices mais avançados, muito utilizados no PostgreSQL para trabalhar com tipos de dados complexos.
O GIN (Generalized Inverted Index) é excelente para:
- arrays
- JSONB
- Full Text Search
Ele funciona de forma parecida com o índice de um livro. A palavra “Java”, por exemplo, aponta para todas as páginas em que aparece.
Já o GiST (Generalized Search Tree) é extremamente versátil e muito usado para:
- dados geográficos
- coordenadas espaciais
- intervalos temporais
- buscas de proximidade
Índice Full-Text
Diferente de índices tradicionais, o índice Full-Text “quebra” o conteúdo textual em partes menores chamadas tokens.
Ele é ideal para mecanismos de busca internos, permitindo pesquisar palavras dentro de textos longos, descrições e documentos.
Índice Espacial (R-Tree)
O índice espacial é otimizado para dados multidimensionais, como latitude e longitude.
Seu principal uso é em consultas geográficas, por exemplo:
- encontrar restaurantes em um raio de 5 km
- localizar pontos próximos em um mapa
- trabalhar com sistemas de geolocalização
Nem tudo são flores: o custo do índice
Embora índices acelerem muito a leitura, eles também possuem um custo.
Toda vez que ocorre um INSERT, UPDATE ou DELETE, o banco de dados precisa:
- atualizar os dados da tabela
- atualizar também as estruturas dos índices
Isso significa que quanto mais índices existirem, maior será o custo das operações de escrita.
Por esse motivo, índices devem ser criados com estratégia. A recomendação mais comum é indexar colunas frequentemente utilizadas em:
- WHERE
- JOIN
- ORDER BY
- GROUP BY
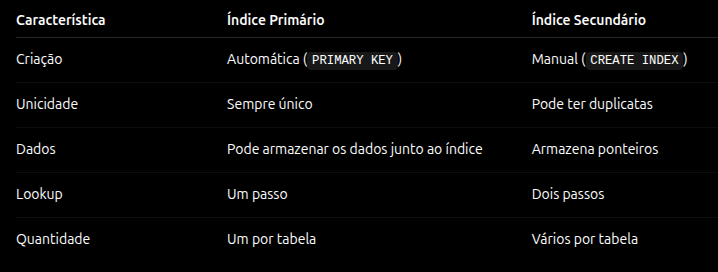
Índice primário vs. índice secundário
Índice primário
O índice primário é construído sobre a chave primária da tabela, normalmente a coluna id.
Ele é criado automaticamente quando definimos uma PRIMARY KEY.
sqlCREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT,
nome TEXT
);Suas principais características são:
- valores únicos
- não aceita NULL
- normalmente organizado fisicamente junto dos dados
Em mecanismos como o InnoDB do MySQL, os dados da tabela ficam fisicamente organizados na ordem do índice primário. Isso é chamado de Clustered Index.
Na prática, buscar pelo id significa acessar diretamente os dados da linha.
Índice secundário
O índice secundário é qualquer índice criado sobre outras colunas da tabela.
Exemplo:
sqlCREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_users_status_data
ON users(status, created_at);Diferente do índice primário, ele não armazena diretamente os dados da linha. Em vez disso, ele guarda:
- o valor indexado
- um ponteiro para a linha real
No InnoDB, esse ponteiro é a chave primária. Já no PostgreSQL, ele aponta para o endereço físico da linha (ctid).
Isso significa que a busca ocorre em dois passos:
- localizar o ponteiro no índice
- acessar a linha real na tabela
Mesmo assim, continua sendo muito mais eficiente do que percorrer toda a tabela.
A diferença na prática
Imagine uma biblioteca.
O índice primário seria a organização física das estantes. Cada livro possui uma posição única e está armazenado exatamente naquele local.
Já o índice secundário funciona como um catálogo por autor. Você procura o nome do autor, encontra a referência da estante e depois vai até ela buscar o livro.
Existe um passo extra, mas ainda é muito mais rápido do que procurar manualmente em toda a biblioteca.
O custo oculto dos índices secundários
Cada índice secundário adicional aumenta o custo das operações de escrita.
Imagine uma tabela com cinco índices secundários. Toda vez que um INSERT for executado, o banco precisará atualizar:
- a tabela
- os cinco índices
Em sistemas com alto volume de escrita, isso impacta diretamente a performance.
Por isso, criar índices é sempre um trade-off: você sacrifica parte da velocidade de escrita para ganhar performance em leitura.
Exemplo ilustrativo
Imagine uma escola com 2 milhões de alunos.
Existe uma sala gigantesca cheia de fichas físicas contendo:
- nome
- matrícula
- turma
- telefone
Agora imagine alguém dizendo:
“Procure a ficha da Maria Silva.”
Sem índice
A única solução seria pegar ficha por ficha até encontrar o nome desejado:
- Ana Souza
- Carlos Lima
- Fernanda Alves
- João Pedro
- Maria Silva
Se Maria estiver no final, praticamente todas as fichas precisarão ser analisadas.
Isso equivale ao banco executando um Full Table Scan.
Com índice
Agora imagine um armário auxiliar contendo apenas:

Você procura “Maria Silva” no índice.
O índice informa a gaveta F09.
Então você vai diretamente até a ficha correta, sem precisar analisar todas as outras.
É exatamente assim que os índices aceleram consultas em bancos de dados.
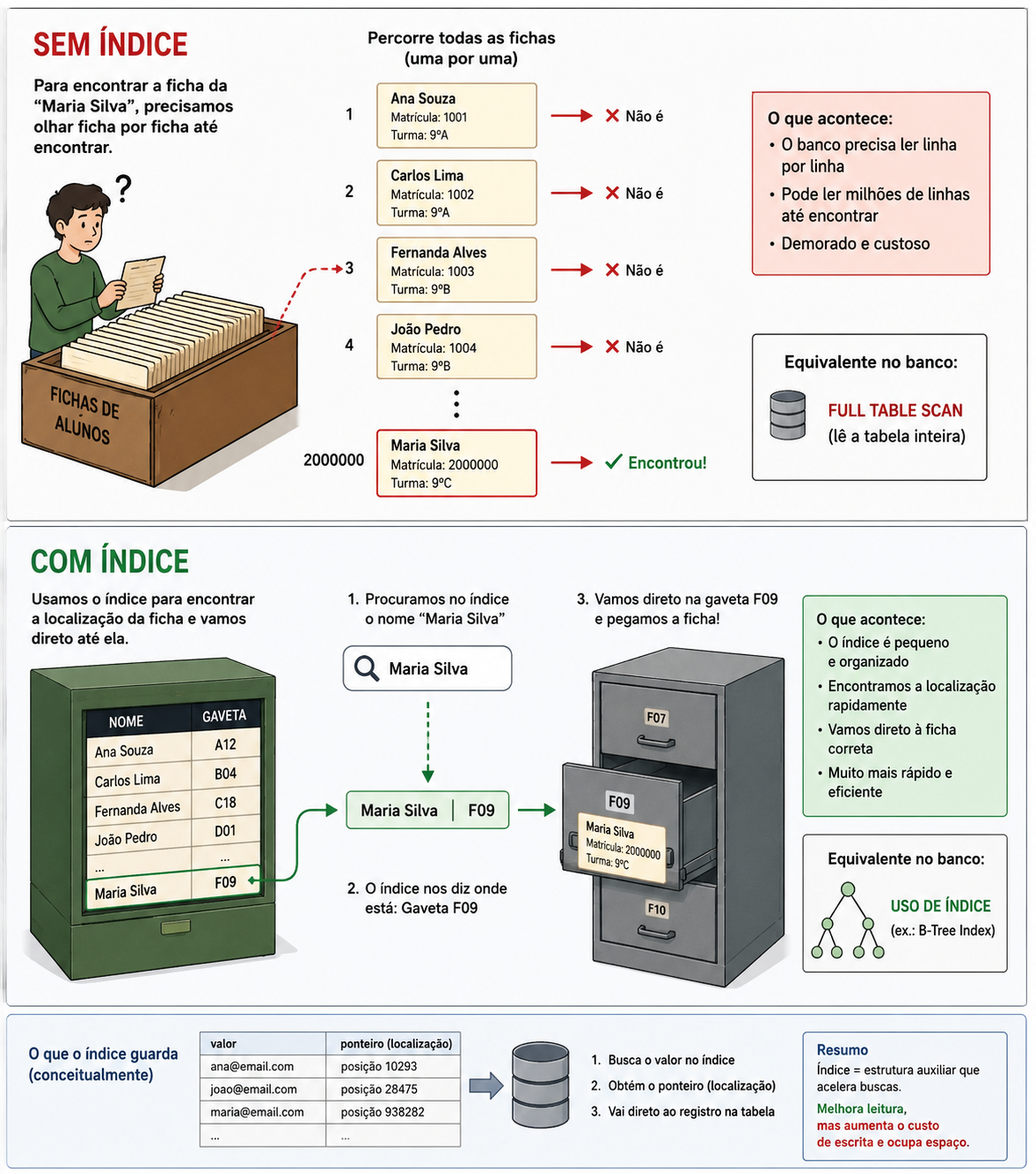
Imagem do exemplo ilustrativo.
Conclusão
Os índices são uma das principais estruturas responsáveis pela performance em bancos de dados. Eles transformam buscas lentas e lineares em operações extremamente rápidas e eficientes.
Ao mesmo tempo, índices não devem ser tratados como solução universal. Cada índice criado adiciona custo de manutenção ao sistema, especialmente em operações de escrita.
Por isso, dominar índices não significa sair indexando tudo, mas entender o comportamento da aplicação, o padrão das consultas e os gargalos reais do sistema.
No fim, um bom design de banco de dados está muito mais relacionado a decisões inteligentes do que à quantidade de índices criados.
Se você chegou até aqui, espero que o artigo tenha ajudado a entender melhor como funcionam os índices em bancos de dados e por que eles são tão importantes para performance.
Obrigado pela atenção e até breve. 😁
Laryssa Ramos
