Hello world 😁 💻
No artigo de hoje iremos explorar uma peça fundamental do ecossistema Java: o JMM, ou Java Memory Model.
Mas afinal, o que é o JMM?
O Java Memory Model é um conjunto de regras e especificações que define como as threads do Java interagem com a memória e entre si. Ele faz parte da própria especificação da linguagem Java e existe para garantir que o comportamento de aplicações concorrentes seja previsível, independentemente do hardware ou sistema operacional onde o programa está sendo executado.
Na prática, o JMM responde perguntas importantes como:
- Quando uma variável modificada por uma thread se torna visível para outra?
- Em que ordem as instruções realmente são executadas?
- Como evitar comportamentos imprevisíveis em código concorrente?
Aqui no blog já existe um artigo explicando o conceito de Threads no contexto do sistema operacional e o que uma thread realmente é. Caso queira ler antes, ele está disponível aqui: Threads
Por que o JMM existe?
Computadores modernos possuem hierarquias complexas de memória. Existem registradores, múltiplos níveis de cache (L1, L2 e L3) e a memória RAM. Para melhorar performance, tanto o hardware quanto o compilador realizam diversas otimizações, como reordenação de instruções e armazenamento temporário de dados em cache.
Sem o JMM, uma thread poderia atualizar uma variável e esse valor permanecer apenas no cache do processador, enquanto outra thread continuaria lendo um valor antigo da memória. Isso abriria espaço para inconsistências extremamente difíceis de detectar.
O papel do JMM é justamente estabelecer regras claras de visibilidade e ordenamento para evitar esse tipo de problema.
Os três pilares do JMM
Para garantir integridade em ambientes multithread, o JMM se apoia em três conceitos principais:
Atomicidade
Garante que determinadas operações aconteçam de forma indivisível, sem interrupções no meio do processo. No Java, leituras e escritas simples de variáveis primitivas normalmente são atômicas.
Visibilidade
Garante que alterações feitas por uma thread possam ser vistas pelas demais threads no momento correto.
Ordenamento
Garante que as instruções sigam uma ordem lógica consistente, impedindo que otimizações do compilador ou do processador quebrem a lógica concorrente da aplicação.
O conceito central: happens-before
O JMM não define seu funcionamento em termos de cache, registradores ou detalhes específicos do hardware. Em vez disso, ele utiliza uma relação abstrata chamada happens-before.
Se uma operação A happens-before (acontece-antes) de uma operação B, então duas garantias passam a existir:
- tudo que A escreveu será visível para B
- a ordem entre elas não poderá ser invertida
Essa relação é estabelecida por algumas regras fundamentais da linguagem:
- Ordem dentro de uma thread: Dentro de uma mesma thread, as instruções seguem a ordem definida no programa.
- Monitor lock: O desbloqueio de um bloco synchronized happens-before de qualquer bloqueio subsequente do mesmo monitor.
- Campos volatile: Uma escrita em um campo volatile happens-before de toda leitura subsequente desse mesmo campo.
- Inicialização de threads: Uma chamada para thread.start() happens-before de qualquer instrução executada dentro da nova thread.
- Finalização de threads: Tudo que acontece dentro de uma thread happens-before do retorno de thread.join().
OBS: O thread.start() é o comando que dá vida a uma thread: é ele que diz para a JVM começar a executar aquela linha de código em paralelo com o resto do programa. Sem ele, a thread existe como objeto mas não faz nada. Já o thread.join() faz o oposto: ele manda a thread atual esperar até que aquela outra termine antes de continuar.
O que o JMM permite que a JVM faça
Para melhorar desempenho, a JVM e o compilador possuem liberdade para realizar algumas otimizações:
- reordenar instruções, desde que o resultado lógico da thread permaneça o mesmo;
- armazenar valores temporariamente em registradores ou cache;
- eliminar operações redundantes.
O JMM define os limites dessas otimizações. Elas podem acontecer livremente desde que não violem nenhuma relação de happens-before estabelecida.
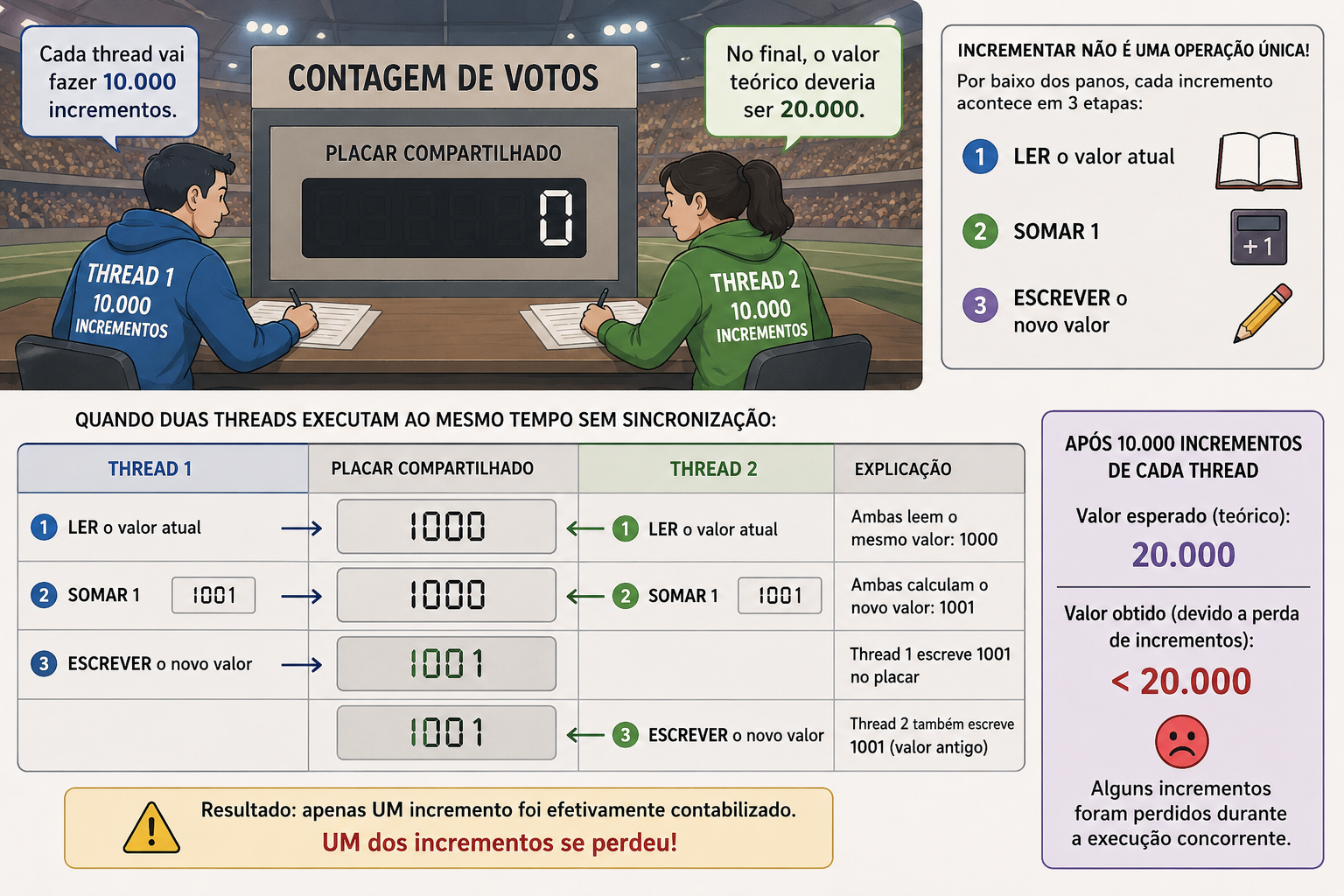
Exemplo: contador concorrente com duas threads
Imagine que você precise contar 20 mil votos. Para acelerar o processo, duas pessoas ficam responsáveis pela contagem, cada uma registrando 10 mil votos no mesmo placar compartilhado.
Em programação concorrente, isso seria equivalente a duas threads manipulando a mesma variável ao mesmo tempo.
Cada thread executa 10 mil incrementos e, teoricamente, o resultado final deveria ser 20 mil.
O problema é que incrementar um contador não é uma operação única. Por baixo dos panos, o processo acontece em três etapas:
- ler o valor atual
- somar 1
- escrever o novo valor
Quando duas threads executam isso simultaneamente sem sincronização, ambas podem ler o mesmo valor antes que qualquer uma escreva o resultado atualizado. Nesse cenário, um dos incrementos simplesmente se perde.
O exemplo abaixo demonstra esse problema:
Agora vamos observar esse problema no código:
javapublic class ContadorInseguro {
private int counter = 0;
public void incrementar() {
counter++; // lê, soma, escreve — três passos sem proteção
}
public static void main(String[] args) throws InterruptedException {
ContadorInseguro c = new ContadorInseguro();
Thread threadA = new Thread(() -> {
for (int i = 0; i < 10000; i++) c.incrementar();
});
Thread threadB = new Thread(() -> {
for (int i = 0; i < 10000; i++) c.incrementar();
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
System.out.println("Resultado: " + c.counter);
System.out.println("Esperado: 20000");
}
}
Exemplo de código sem tratamento das Threads
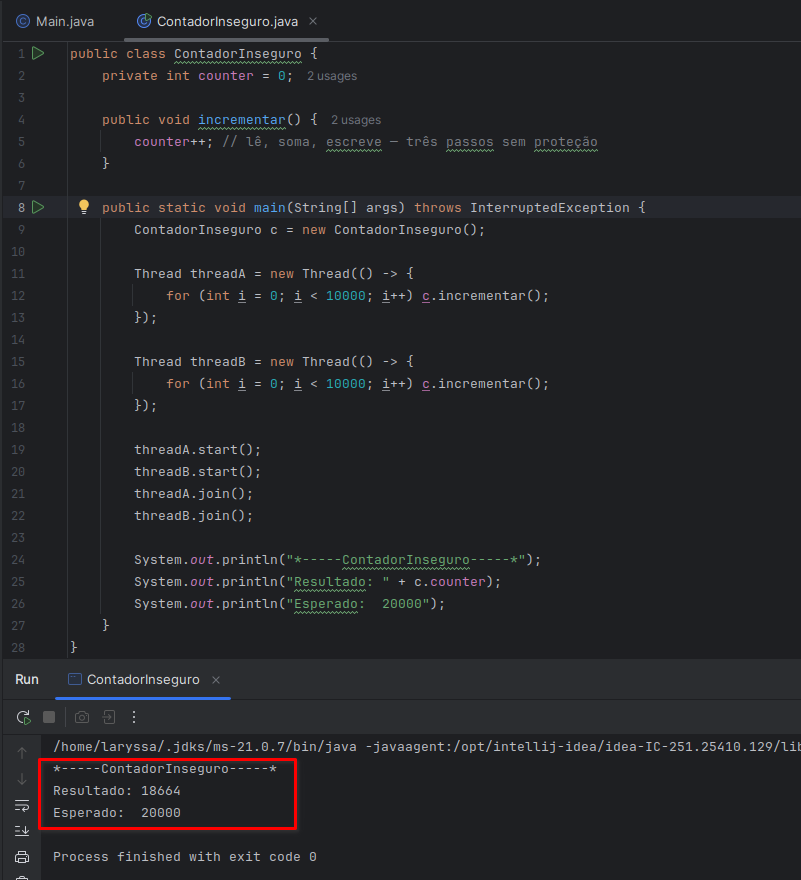
Resultado do programa
O resultado deveria ser sempre 20.000, mas se o programa for executado várias vezes, o valor final provavelmente mudará a cada execução. Às vezes 18.664, às vezes 18.203, às vezes outro número qualquer.
Isso acontece por causa da condição de corrida entre as threads.
Agora vamos resolver o problema usando synchronized:
javapublic class ContadorSynchronized {
private int counter = 0;
public synchronized void incrementar() {
counter++;
}
public static void main(String[] args) throws InterruptedException {
ContadorSynchronized c = new ContadorSynchronized();
Thread threadA = new Thread(() -> {
for (int i = 0; i < 10000; i++) c.incrementar();
});
Thread threadB = new Thread(() -> {
for (int i = 0; i < 10000; i++) c.incrementar();
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
System.out.println("*-----ContadorSynchronized-----*");
System.out.println("Resultado: " + c.counter); // sempre 20000
System.out.println("Esperado: 20000");
}
}Exemplo de código com tratamento das Threads
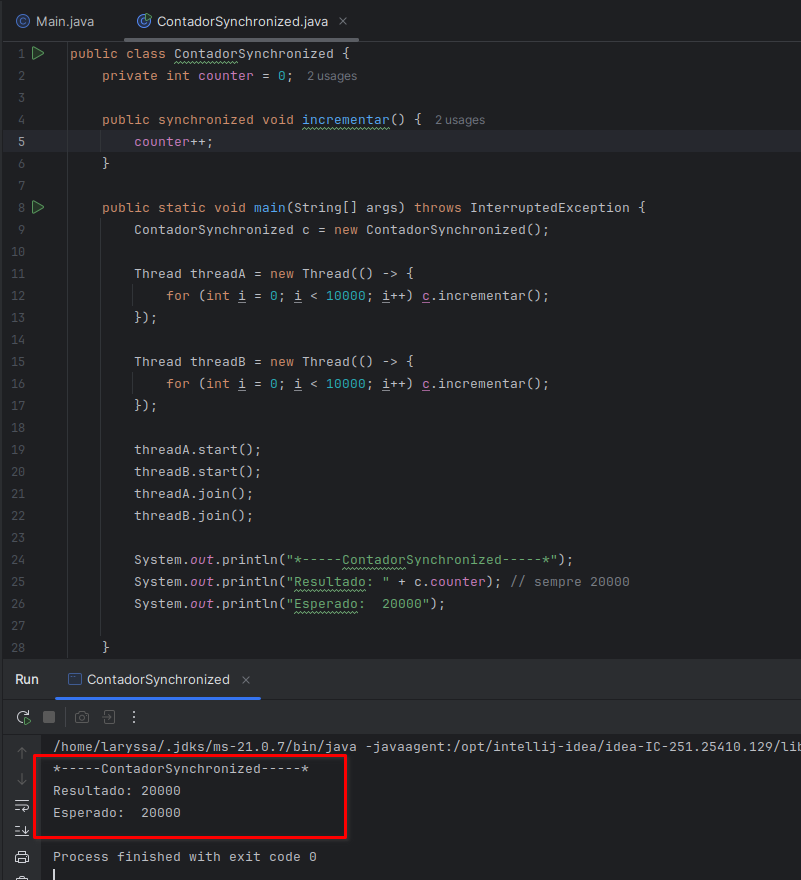
Resultado do programa
Nesse caso, o resultado será sempre 20.000.
O synchronized funciona como um mecanismo de exclusão mútua: apenas uma thread por vez pode executar o trecho protegido. Isso impede que duas threads alterem o contador simultaneamente.
synchronized não é a única solução
O synchronized é uma das formas mais tradicionais de sincronização no Java, mas não é a única.
O AtomicInteger, por exemplo, resolve o problema do contador sem utilizar um lock tradicional. Ele utiliza operações atômicas fornecidas diretamente pelo processador, o que costuma ser mais eficiente para casos simples como incremento de variáveis.
Já o ReentrantLock funciona de maneira semelhante ao synchronized, mas oferece mais controle ao programador. Com ele é possível, por exemplo, tentar adquirir um lock por tempo limitado, interromper tentativas de espera ou criar estratégias mais elaboradas de coordenação entre threads.
A escolha depende muito do contexto.
Para um contador simples, AtomicInteger normalmente é suficiente. Já para operações maiores, onde múltiplas ações precisam acontecer juntas de forma segura, synchronized ou ReentrantLock costumam fazer mais sentido.
Apesar das diferenças, todas essas ferramentas possuem algo em comum: elas estabelecem relações de happens-before dentro da aplicação, garantindo visibilidade e ordenamento entre as threads.
Conclusão
O Java Memory Model existe porque computadores modernos são rápidos e complexos demais para funcionar de maneira ingênua. Processadores reordenam instruções, caches armazenam valores temporariamente e múltiplas threads executam simultaneamente em núcleos diferentes.
Sem regras claras sobre visibilidade e ordenamento, qualquer aplicação concorrente se tornaria imprevisível.
O JMM não elimina a complexidade da concorrência, mas fornece um conjunto de garantias que permite ao programador trabalhar com ela de forma segura e consistente.
Palavras como synchronized e volatile não são apenas detalhes de sintaxe. Elas representam contratos explícitos com a JVM, indicando onde a ordem importa e quais informações precisam ser compartilhadas corretamente entre as threads.
No fim, programar com concorrência é aprender que algo aparentemente simples pode não ser tão simples assim: a ordem em que as coisas acontecem importa muito mais do que parece.
Se você chegou até aqui, espero que o artigo tenha ajudado a esclarecer melhor o que é o JMM e por que ele é tão importante em aplicações Java.
Obrigada pela atenção e até breve.😁
Laryssa Ramos.
